計算機科学の基本的概念 チューリングマシン
目次
- はじめに
- チューリングマシンの歴史
- チューリングマシンの基本概念
- チューリングマシンの応用
- チューリングマシンとコンピュータの関係
- チューリングマシンの限界と問題
はじめに
計算機科学の基本的な概念である「チューリングマシン」についてまとめます。チューリングマシンは、現代のコンピュータシステムの基礎となっている考え方であり、計算能力やアルゴリズムの理解に不可欠です。チューリングマシンの歴史や基本概念、応用、限界に焦点を当ててまとめていきます。
チューリングマシンの概要
チューリングマシンは、イギリスの数学者アラン・チューリングが1936年に考案した抽象的な計算モデルです。無限の長さのテープと、そのテープ上の記号を読み書きするためのテープヘッド、状態遷移ルールによって構成されています。チューリングマシンは、あらゆる計算問題を解く能力があるとされており、これを「チューリング完全」と呼びます。
チューリングマシンの発表は、計算機科学の歴史において画期的な出来事でした。それまで形式化されていなかった「計算」という概念を数学的に定義することに成功し、これにより現代のコンピューターやプログラミング言語の基礎が築かれました。
このブログでは、チューリングマシンの歴史と基本概念から応用までを解説し、さらにチューリングマシンと現代のコンピュータの関係やチューリングマシンの限界といったトピックについても触れていきます。
チューリングマシンの歴史
アラン・チューリングの業績
アラン・チューリング(1912-1954)は、イギリスの数学者であり、コンピュータ科学、人工知能、暗号解読の分野において非常に重要な業績を残した人物です。彼は、現代のコンピュータ科学の礎を築いたとも言われています。

チューリングは、1936年に「決定問題」に関する論文を発表し、これがチューリングマシンの誕生となりました。この論文では、彼は数学的な問題を解決するための汎用機械、すなわちチューリングマシンの概念を紹介し、計算可能性という概念を定式化しました。
第二次世界大戦中、チューリングはイギリス政府の暗号解読部門に勤務し、ドイツ軍の暗号「エニグマ」の解読に成功しました。彼の貢献は、戦争の勝利に大きく影響し、多くの命が救われました。この暗号解読の過程で、彼は機械式の解読装置「ボンベ」を開発し、計算機の歴史にも大きな足跡を残しました。
戦後、チューリングは人工知能の分野に焦点を当てました。彼は、機械が人間のように思考することができるかどうかを試すための基準として、現在「チューリングテスト」として知られる方法を提案しました。これは、コンピュータがどの程度人間のような知性を持っているかを判断するための試験であり、現代のAI研究においても重要な指標となっています。
チューリングマシンの登場背景
チューリングマシンの登場背景には、1930年代の数学界での論争が関係しています。当時、数学者たちは「決定問題」と呼ばれる問題に取り組んでいました。これは、ある数学的な命題が真か偽かを決定するアルゴリズムが存在するかどうかを問う問題です。
ドイツの数学者デビッド・ヒルベルトは、すべての数学的問題に対して解決策が存在すると信じており、決定問題にもアルゴリズムによる解決策が存在すると考えていました。しかし、アラン・チューリングは、そのようなアルゴリズムが存在しないことを示すために、チューリングマシンの概念を提案しました。
チューリングマシンは、すべての計算を行うことができる理想的な機械として設計されており、それによって計算可能性の範囲を明確に定義しました。彼は、チューリングマシンが計算できない問題は、原理的にどのようなアルゴリズムでも解決できないと主張しました。これにより、決定問題への否定的な解答が与えられ、数学の基礎に関する考え方が変わりました。
また、チューリングマシンの登場は、現代のコンピュータ科学や人工知能の発展にも大きな影響を与えました。チューリングマシンが提案されたことで、計算機の抽象モデルが確立され、後に現れる電子式のコンピュータやプログラミング言語の設計に寄与しました。そのため、チューリングマシンは、現代のコンピュータ技術の基盤となる重要な発明とされています。
チューリングマシンの基本概念
チューリングマシンは、抽象的な計算モデルであり、計算の本質を捉えることを目的としています。以下に、チューリングマシンの主要な概念を説明します。

無限のテープ
チューリングマシンは、無限に長いテープとそれを操作するテープヘッドから構成されます。このテープは、セルに分割されており、各セルには1つの記号が書かれています。テープ上のセルには、あらかじめ入力データが格納されており、計算が進むにつれてテープに書かれた情報が更新されます。
記号の読み書き
テープヘッドは、現在のセルの記号を読み取り、新しい記号を書き込むことができます。読み取られた記号は、次にどの操作を行うかを決定するために使用されます。
テープヘッドの移動
テープヘッドは、テープ上を左右に移動することができます。各ステップで、テープヘッドは現在のセルから左隣のセル、右隣のセル、または同じセルに移動します。これにより、テープ上の異なるセルにアクセスして情報を読み書きすることができます。
状態遷移
チューリングマシンは、状態遷移を用いて計算を行います。状態遷移は、読み取られた記号と現在の状態に基づいて、次のアクション(記号の書き込み、テープヘッドの移動、次の状態への遷移)を決定します。チューリングマシンは、計算が完了するか、停止状態に達するまで状態遷移を繰り返します。
チューリング完全性
チューリング完全とは、ある計算モデルがチューリングマシンと同等の計算能力を持つことを意味します。チューリング完全なシステムは、チューリングマシンが解決できる任意の計算問題を解決することができます。これは、チューリングマシンが現代コンピュータの基礎となる理論的モデルであることを示しています。
チューリングマシンの応用
チューリングマシンは、その理論的な基盤から、様々な分野において応用されています。このセクションでは、計算機科学、人工知能、暗号理論といった代表的な分野におけるチューリングマシンの応用について説明します。
計算機科学
チューリングマシンは、計算機科学の基本的な理論として位置づけられています。アルゴリズムの正確性や計算量、計算可能性、複雑性の理論を分析する際に、チューリングマシンが用いられます。例えば、問題を解決するためのアルゴリズムがある場合、そのアルゴリズムをチューリングマシンで表現することで、アルゴリズムの性能や限界を理論的に評価することができます。
人工知能
チューリングマシンは、人工知能(AI)研究にも重要な役割を果たしています。AIの目標は、人間の知能を模倣または超越する機械やシステムを作成することです。チューリングは、彼の有名な「チューリングテスト」を提案し、機械が人間の知能を模倣できるかどうかを評価する基準を定めました。このテストは、チューリングマシンの理論に基づいており、現代のAI研究においても、機械学習や深層学習などの手法が開発される際に、チューリングマシンの概念が参照されることがあります。
暗号理論
暗号理論は、情報の保護や秘匿性を確保するための手法を研究する分野です。チューリングマシンは、暗号の強度や解読の困難さを理論的に評価するのに役立ちます。チューリング自身が、第二次世界大戦中にドイツ軍の暗号「エニグマ」を解読するために、暗号解読マシン「ボンベ」を開発しました。これは、チューリングマシンの考え方を応用したものであり、現代の暗号技術にも影響を与えています。
現代の暗号技術では、量子コンピュータに対抗するポスト量子暗号など、新しい暗号アルゴリズムの開発が進められています。これらのアルゴリズムを評価する際にも、チューリングマシンの概念が用いられており、暗号アルゴリズムの安全性や効率性を理論的に分析することが可能です。
また、ブロックチェーン技術やスマートコントラクトのような分散型システムの設計においても、チューリング完全なコンピュータ言語を利用することで、柔軟なプログラミングが可能となります。これにより、暗号通貨やデータ保護、デジタルアイデンティティ管理などの分野で、チューリングマシンの理論が活用されています。
総じて、チューリングマシンは計算機科学、人工知能、暗号理論などの様々な分野において、その理論的基盤として用いられており、これらの分野の発展に大きく貢献しています。チューリングマシンの理論は、未来の技術革新にも引き続き影響を与えることでしょう。
チューリングマシンとコンピュータの関係
チューリングマシンは、抽象的な計算モデルとしてコンピュータの基本概念を定義するのに非常に重要な役割を果たしています。このセクションでは、チューリングマシンの抽象化、現代コンピュータの起源、およびチューリング完全なコンピュータ言語について説明します。
チューリングマシンの抽象化
チューリングマシンは、アラン・チューリングが1936年に考案した抽象的な計算モデルです。このモデルは、無限長のテープ、テープ上の記号の読み書き、テープヘッドの移動、および状態遷移を使用して、あらゆる計算問題を解決することができます。チューリングマシンは、計算可能性とアルゴリズムの概念を形式化するための基本的な道具であり、コンピュータ設計の基礎となる考え方を提供しています。
現代コンピュータの起源
現代のコンピュータは、チューリングマシンの概念に深く根ざしています。チューリングマシンが提案された後、コンピュータのハードウェアとソフトウェアの設計において、テープをメモリ、テープヘッドをプロセッサ、状態遷移を命令セットという具体的な形で実装することが可能になりました。また、ストアード・プログラム・コンセプト(メモリ内にプログラムを格納する概念)も、チューリングマシンの影響を受けています。
チューリング完全なコンピュータ言語
チューリング完全とは、ある言語やシステムがチューリングマシンと同等の計算能力を持つことを意味します。チューリング完全な言語は、理論的にはあらゆる計算問題を解決することができます。多くの現代のプログラミング言語(C, Java, Pythonなど)はチューリング完全であり、これにより、これらの言語を使用して様々なアプリケーションやシステムを構築することが可能になっています。
まとめると、チューリングマシンは、現代コンピュータの基本概念と設計原理に深い影響を与えています。抽象化された計算モデルとして、チューリングマシンは計算機科学の基礎を築いており、その概念は現代のコンピュータアーキテクチャやプログラミング言語にも見られます。チューリング完全な言語は、コンピュータがどのような問題を解決できるかを理解するための重要な基準となっており、現代のプログラミング言語はこの基準を満たすことで、あらゆる計算問題に対処できる柔軟性を持っています。
チューリングマシンの抽象化がもたらす理論的な枠組みは、計算機科学や情報技術の発展に大きく貢献し、現代社会においてコンピュータが果たす重要な役割を理解する上で欠かせないものとなっています。
チューリングマシンの限界と問題
チューリングの停止問題
チューリングマシンの重要な限界の1つは、停止問題です。停止問題とは、あるチューリングマシンが与えられた入力に対して停止するかどうかを判断する問題です。アラン・チューリングは、一般的なアルゴリズムを用いて停止問題を解決することは不可能であることを示しました。これは、どんなに高性能なコンピュータを使っても、すべてのプログラムがいつ終了するかを予測することはできないことを意味します。
計算資源の制約
チューリングマシンは理論上無限のテープを持つとされていますが、現実のコンピュータは有限のメモリと処理能力を持っています。そのため、現実の問題を解決する際には、チューリングマシンの理想的なモデルからは大きくかけ離れた状況で計算資源の制約に直面します。
計算の非効率性
チューリングマシンは、計算の進行に従ってテープ上を左右に移動しながら記号を読み書きします。しかし、このような逐次的な計算プロセスは、現実の問題に対して非効率的であることがあります。例えば、並列処理を活用することで、計算の効率を大幅に向上させることが可能です。
量子コンピュータとの関係
量子コンピュータは、量子力学を利用して計算を行う新しいコンピューティングパラダイムです。量子コンピュータは、従来のチューリングマシンモデルとは異なる計算モデルを採用しており、一部の問題に対してはチューリングマシンよりもはるかに高速に計算することができます。そのため、量子コンピュータが普及すれば、チューリングマシンの限界を超える計算能力が実現される可能性があります。
チューリングマシンと現実の問題
チューリングマシンは、計算の抽象的なモデルとして非常に重要ですが、現実の問題に対処する際には、さまざまな要因が計算の性質や効率に影響を与えることがあります。例えば、アルゴリズムの選択、データ構造、ハードウェアの性能、プログラム言語の特性などが、実際の計算プロセスに大きく影響します。チューリングマシンは、理論上の計算能力を示すモデルであるため、これらの現実的な問題に対処するための具体的なガイダンスを提供することはできません。
チューリングマシンの非決定性
非決定性チューリングマシンは、複数の可能な遷移が同時に存在することが許されるチューリングマシンの拡張です。非決定性チューリングマシンは、いくつかの計算問題に対して効率的なアルゴリズムを提供することができますが、現実のコンピュータでは非決定性の計算を直接実現することが難しいです。このため、非決定性チューリングマシンの理論上の利点を現実の計算環境にどのように適用するかという問題が残されています。
低ランク行列近似によるLLMの計算効率化手法
LoRA: Low-Rank Adaptation of Large Language Models
元論文 arxiv.org
公式実装 github.com
目次
- はじめに
- LoRAの概要
- LLMへの適用方法
- 実験と評価
- LoRAの利点と応用例
- まとめと今後の展望
はじめに
LLMの課題
近年、LLM(大規模言語モデル)が多くの自然言語処理タスクで顕著な成果を上げています。一般的に、これらのモデルは非常に多くのパラメータを持っており、特定のドメインやタスクへの適応を行う際には、大量のデータと計算リソースが必要となることが課題となっています。また、モデルのサイズが大きくなることで、デバイスのメモリや計算能力が制約される環境での使用が困難になる場合もあります。
LoRAの目的
LoRA(Low-Rank Adaptation)は、この課題に取り組むためにMicrosoftによって開発されました。LoRAの目標は、LLMのパラメータを低ランク行列で近似することにより、適応の際に必要な計算量とメモリ使用量を大幅に削減し、タスクやドメイン固有のデータで迅速かつ効率的にモデルを微調整することができるようにすることです。これにより、LLMをより実用的で効果的なツールに進化させることが期待されています。
LoRAの概要
低ランク行列近似の考え方
LoRAは、低ランク行列近似という手法を用いて、LLMのパラメータを効率的に表現します。低ランク行列近似とは、元の行列をランクが低い行列の積に分解することで、行列の構造を簡略化し、情報を圧縮する方法です。具体的には行列の特異値分解(SVD)や主成分分析(PCA)のような技術が利用されます。
この手法を言語モデルに適用することで、モデルのパラメータを近似的に表現し、タスク固有のデータでモデルを効率的に微調整できるようになります。低ランク行列近似によって、モデルの性能を維持しつつも、パラメータ数を大幅に削減することが期待されます。

LoRAの利点
- Adamなど状態を保持するタイプのオプティマイザを使用する場合、VRAM使用量を最大で2/3に削減することができます
- GPT-3 175Bでは、トレーニング中のVRAM消費量を1.2TBから350GBに削減
- チェックポイントで保存されるモデルサイズが約 1/10000 に削減されます
- ファインチューニングが高速化されます
- GPT-3 175Bでのトレーニングでは、パラメータの大部分について勾配を計算する必要がないためフルファインチューニングと比較して25%のスピードアップ
LLMへの適用方法
モデルアーキテクチャの選択
LoRAは、さまざまなLLMアーキテクチャに適用可能です。例えば、GPTやBERTのようなトランスフォーマーベースのモデルや、LSTMやGRUのようなリカレントニューラルネットワーク(RNN)ベースのモデルにも利用できます。適用するモデルアーキテクチャは、タスクやドメインの要件に応じて選択することができます。
パラメータの初期化と微調整
LoRAを適用する際の手順は次のようになります。
- ベースモデル(例:LLaMA)を選択し、そのパラメータを事前学習済みの状態に初期化します。
- ベースモデルのパラメータ行列を低ランク行列(UとV)に分解します。この分解は、特異値分解(SVD)などの行列分解手法を使用して行われます。
- 分解された低ランク行列UとVを、新しいタスクやドメイン固有のデータで微調整します。この微調整プロセスは、通常のモデル微調整と同様に、確率的勾配降下法(SGD)やAdamなどの最適化アルゴリズムを用いて行われますが、パラメータの数が大幅に削減されているため、計算コストとメモリ使用量が大幅に低減されます。
- 微調整された低ランク行列UとVを用いて、タスクやドメインに適応させたモデルを構築します。最終的なモデルは、元のベースモデルと同じアーキテクチャを持ちますが、パラメータがタスクやドメイン固有の情報で更新されています。
実験と評価
LoRAの性能評価
LoRAの性能を評価するために、論文ではいくつかの自然言語処理(NLP)タスクが選択されました。これらのタスクは、機械翻訳、質問応答、文書分類など、さまざまな分野をカバーしています。これらのタスクに対するLoRAの性能を、従来のLLMの微調整手法と比較して評価しました。
LoRAは各NLPタスクにおいて、既存の微調整手法と比較して同等またはそれ以上の性能を達成しています。さらに、LoRAを使用することで、訓練リソースとメモリ使用量が大幅に削減されることが示されました。これは、LoRAが効率的かつ迅速にタスク固有のモデルを適応させることができることを意味します。

LoRAの利点と応用例
タスク固有の微調整の効率化
LoRAは、低ランク行列近似を用いてLLMの適応プロセスを効率化します。このアプローチにより、タスク固有の微調整が迅速かつ効率的に行えるため、短時間で高い性能を達成できます。また、LoRAを用いた微調整は、既存の微調整手法と比較して同等またはそれ以上の性能を達成することが実証されています。
ドメイン固有の適応への応用
特定のドメインや業界に特化した言語モデルを開発する際、LoRAは大いに役立ちます。例えば、医療、法律、金融などの専門的なドメインで、既存のLLMを適応させることが可能になります。このようなドメイン固有の適応は、専門家の知識を活用してモデルをより正確かつ効果的にするために重要です。
リソース制約環境での使用
リソース制約のある環境では、LoRAを使用することでLLMの適応と実行が可能になります。低ランク行列近似によって計算量とメモリ使用量が大幅に削減されるため、限られたリソースでも高い性能が実現できます。これにより、小規模なデバイスやリソースが制限された状況下でも、LLMを効果的に活用することができます。
まとめと今後の展望
LoRAの貢献とインパクト
LoRA(Low-Rank Adaptation)は、LLMの適応能力を向上させる革新的な手法です。低ランク行列近似を利用することで、計算量とメモリ使用量を大幅に削減し、タスクやドメイン固有のデータで迅速かつ効率的にモデルを微調整することが可能となりました。これにより、LoRAはLLMをさらに実用的で効果的なツールに進化させる可能性があります。また、リソース制約のある環境でも高性能な言語モデルを活用できるため、多くのアプリケーションやビジネスに対するインパクトが期待されます。
LLMの未来への影響
LoRAによる適応能力の向上により、研究や産業での言語モデルの利用がさらに増えることが予想されます。また、リソース制約環境での利用が容易になることで、言語モデル技術がより多くの人々やシチュエーションで使用されるようになるでしょう。
Amazon ECSタスクでのGPUの使用
ECSでGPUを使う機会があったので、やり方をメモする。 2022.09.22時点ではFargateがGPUに未対応だったため、ECSをEC2(GPU)上に展開する方針をとった。 (このIssueを見ると、まもなくFargateがGPUに対応しそう。)
ポイントは
- ECSに最適化されたAMIを使うこと
- クラスタ作成時に「EC2 Linux + ネットワーキング」を選択して、EC2を自動で立ち上げてもらうこと
なお、本作業にあたってこちらのブログを大変参考にさせていただいた。以下の内容の大部分がこの記事と同じものになってしまったが、EC2をECSへ紐づける方法が異なる。
タスクの定義
ECS管理画面のタスク定義に行き、新しい定義の作成をクリックする。
起動タイプの互換性の選択ではEC2を選択- 各項目を次のように入力する。
| 項目 | 値 |
|---|---|
| タスク定義名 | ecs-gpu-test-task-def |
| ネットワークモード | awsvpc |
| タスク実行ロール | なし |
| タスクメモリ (MiB) | 512 |
| タスク CPU (単位) | 512 |
コンテナの追加
| グループ | 項目 | 値 |
|---|---|---|
| スタンダード | コンテナ名 | ecs-gpu-test-container |
| イメージ | nvidia/cuda:9.0-base | |
| プライベートレジストリの認証 | チェックなし | |
| メモリ制限 (MiB) | ソフト制限 512 | |
| ポートマッピング | 入力なし | |
| 環境 | CPU ユニット数 | 512 |
| GPU | 1 | |
| 基本 | チェックあり | |
| エントリポイント | 入力なし | |
| コマンド | sh,-c,nvidia-smi | |
| 作業ディレクトリ | 入力なし | |
| 環境ファイル | 入力なし | |
| ストレージとログ | ログ設定 | チェックあり |
ECSクラスターの作成
ECS管理画面のクラスターに行き、クラスターの作成をクリックする。
- クラスターテンプレートの選択で
EC2 Linux + ネットワーキングを選択する
| グループ | 項目 | 値 |
|---|---|---|
| クラスターの設定 | クラスター名 | ecs-gpu-test-cluster |
| インスタンスの設定 | プロビジョニングモデル | オンデマンドインスタンス |
| EC2 インスタンスタイプ | g4dn.xlarge | |
| インスタンス数 | 1 | |
| EC2 AMI ID | デフォルトでセットされたものを使用 | |
| データ EBS ボリュームサイズ (GiB) | 22 | |
| キーペア | 作成を推奨 | |
| ネットワーキング | VPC | 新しいVPCの作成 |
| CIDRブロック | 10.0.0.0/16 | |
| サブネット1 | 10.0.0.0/24 | |
| サブネット2 | 10.0.1.0/24 | |
| セキュリティグループのインバウンドルール | 0.0.0.0/0, 80 | |
| コンテナインスタンスの IAM ロール | 新しいロールを作成 |
クラスターを作成すると、ECSを展開するためのEC2が起動する。起動したEC2はEC2管理画面から確認できる。
またある程度時間が経過すると、クラスターにEC2が紐付き、ECSインスタンスとして以下のように表示される。

ECSタスクの実行
各項目を以下のように入力する。
| 項目 | 値 |
|---|---|
| 起動タイプ | EC2 |
| タスク定義 | ecs-gpu-test-task-def |
| クラスター | ecs-gpu-test-cluster |
| タスクの数 | 1 |
| クラスターVPC | 10.0.0.0/16 |
| サブネット | どちらか選択できるほう(GPUの場合、タスクの起動に失敗するAZがあるので注意) |
| セキュリティグループ | そのまま |
| パブリック IP の自動割り当て | DISABLED |
| 配置テンプレート | AZバランススプレッド |
タスクの実行をクリックし、タスクを起動する。今回はシェルコマンドを実行するのみのタスクなので、即座にタスクが停止する。ステータスがSTOPPEDになったタスクから、今回実行したタスクをクリックするとコンテナ欄で以下のように表示されているはず。

CloudWatchのログを表示をクリックすると、タスク実行時のログが表示される。以下のようにログが表示されていれば、タスクの実行およびNvidiaドライバーによるGPUの認識に成功している。

まとめ
- ECSをGPUで展開するには2022/10月時点ではECS on EC2しか手が無い。
- ECSクラスター作成時に
EC2 Linux + ネットワーキングを選択することで、簡単にEC2をECSに紐づけることができた。 - 今回は簡単のためにVPCをクラスター作成時に自動作成してもらう方法をとったが、実運用時にはPrivateなセグメントを用意して、そこにECSサービスを配置するように注意されたい。
参考
PythonでGoogle SpeechToText REST API を呼び出す
Pythonで Google Cloud SpeechToText を使用する場合、SpeechToTextクライアントライブラリを使うのが一般的だと思うが、REST API から呼び出す機会があったのでメモ。
REST API の公式仕様はこちらに載っている。 cloud.google.com
準備として、APIキーの取得が必要。 こちらの記事などを参考に取得してください。
音声認識を行う手順は
- ファイルをバイナリで読み込む
- base64で文字列に変換する
- リクエストボディに渡す
speech:recognizeエンドポイントにPOSTリクエスト
少しはまった点で、バイナリはbase64.b64encodeでエンコードしただけではダメで、.decode("utf-8")を作用させる必要があった。
configで指定可能なパラメタは以下を参照。
コードを以下に示す。
import base64 import json import requests API_KEY = "[YOUR API KEY]" if __name__ == "__main__": recognize_url = "https://speech.googleapis.com/v1p1beta1/speech:recognize" url = recognize_url + "?key=%s" % (API_KEY) filepath = "[path to dir]/something.wav" config = { "encoding": "LINEAR16", "languageCode": "ja-JP", "model": "default", "maxAlternatives": 5, "enableWordConfidence": True, "enableWordTimeOffsets": True, "enableAutomaticPunctuation": True, } with open(filepath, "rb") as f: content = base64.b64encode(f.read()).decode("utf-8") payload = {"audio": {"content": content}, "config": config} headers = {"content-type": "application/json"} response = requests.post(url, headers=headers, data=json.dumps(payload)) print(response.json())
時系列モデリング手法 HiPPO を読み解く(2)
本記事では、時系列モデリング手法HiPPOの理解を目指し、著者実装をstep-by-stepで動かす。
参考にする著者実装はこちら。
なお、HiPPOの理論は第一部の記事にまとめたのでそちらも参照されたい。
必要モジュールのインポート
from functools import partial import torch import torch.nn as nn import torch.nn.functional as F import torch.utils.data as data import numpy as np from scipy import signal from scipy import linalg as la from scipy import special as ss import matplotlib.pyplot as plt device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
テスト用データ作成
ノイズを加えた時系列データを作成するための、whitesignal()が用意されている。ノイズの周波数の上限をfreq引数で制御できるため、過度に急峻なノイズが加わることを防ぐことができる。
def whitesignal(period, dt, freq, rms=0.5, batch_shape=()): """ Produces output signal of length period / dt, band-limited to frequency freq Output shape (*batch_shape, period/dt) Adapted from the nengo library """ if freq is not None and freq < 1. / period: raise ValueError(f"Make ``{freq} >= 1. / {period}`` to produce a non-zero signal",) nyquist_cutoff = 0.5 / dt if freq > nyquist_cutoff: raise ValueError(f"{freq} must not exceed the Nyquist frequency for the given dt ({nyquist_cutoff:0.3f})") n_coefficients = int(np.ceil(period / dt / 2.)) shape = batch_shape + (n_coefficients + 1,) sigma = rms * np.sqrt(0.5) coefficients = 1j * np.random.normal(0., sigma, size=shape) coefficients[..., -1] = 0. coefficients += np.random.normal(0., sigma, size=shape) coefficients[..., 0] = 0. set_to_zero = np.fft.rfftfreq(2 * n_coefficients, d=dt) > freq coefficients *= (1-set_to_zero) power_correction = np.sqrt(1. - np.sum(set_to_zero, dtype=float) / n_coefficients) if power_correction > 0.: coefficients /= power_correction coefficients *= np.sqrt(2 * n_coefficients) signal = np.fft.irfft(coefficients, axis=-1) signal = signal - signal[..., :1] # Start from 0 return signal
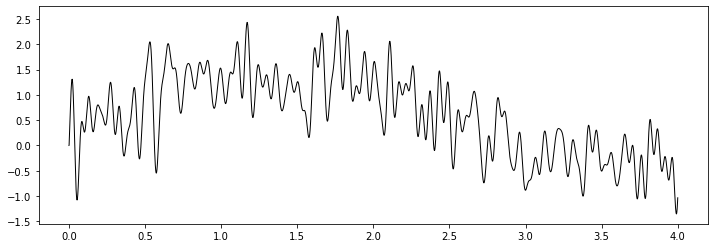
時系列データを作成してプロットしてみよう。
np.random.seed(0) T=4 dt=5e-4 N=64 freq=20.0 vals = np.arange(0.0, T+dt, dt) L = int(T / dt) + 1 u = torch.FloatTensor(whitesignal(T, dt, freq=freq)) u = F.pad(u, (1, 0)) u = u + torch.FloatTensor( np.sin(1.5 * np.pi / T * np.arange(0, T + dt, dt)) ) # add 3/4 of a sin cycle u = u.to(device) plt.figure(figsize=(12, 4)) offset = 0.0 plt.plot(vals, u.cpu() + offset, "k", linewidth=1.0)
HiPPO-LegSのクラスを用意
以下の関数を持つHiPPOScaleクラスを作成する。
__init__(): LTI方程式の係数行列 A,B を計算しておくforward(): 時系列信号を入力としてLTI方程式を解き、係数ベクトル c の時間発展を計算するreconstruct(): 係数ベクトル c から現在までの時系列信号を再構成する
class HiPPOScale(nn.Module): """Vanilla HiPPO-LegS model (scale invariant instead of time invariant)""" def __init__(self, N, max_length=1024): """ max_length: maximum sequence length """ super().__init__() # HiPPO行列 A,B を計算しておく def forward(self, inputs): """ inputs : (length, ...) output : (length, ..., N) where N is the order of the HiPPO projection """ # 時系列信号を入力としてLTI方程式を解き、係数ベクトル c の時間発展を計算する ... def reconstruct(self, c): # 係数ベクトル c から、現在までの時系列信号を再構成する ...
HiPPO行列の計算
LegS測度
のもとでLTI方程式
の係数行列は次のように与えられるのであった。
これは以下のtransition()で計算される。
def transition(N): # Legendre (scaled) # q = np.arange(N, dtype=np.float64) q = np.arange(N, dtype=np.float32) col, row = np.meshgrid(q, q) r = 2 * q + 1 M = -(np.where(row >= col, r, 0) - np.diag(q)) T = np.sqrt(np.diag(2 * q + 1)) A = T @ M @ np.linalg.inv(T) B = np.diag(T)[:, None] B = ( B.copy() ) # Otherwise "UserWarning: given NumPY array is not writeable..." after torch.as_tensor(B) return A, B
試しにN=3でHiPPO行列を計算してみる。
A, B = transition(3) B = B.squeeze(-1)
まず行列Aの成分を確認しよう。
# print(A) [[-1. 0. 0. ] [-1.7320508 -1.9999999 0. ] [-2.236068 -3.8729835 -3. ]]
に関して対角成分は
下三角の非対角成分は であることが確認できる。
次に行列Bの成分を確認しよう。
# print(B) [1. 1.7320508 2.236068 ]
各成分がであることが確認できる。
離散化した常微分方程式による時間発展
Bilinear法では以下の式で係数cが更新される。
max_length = L
A, B = transition(N)
B = B.squeeze(-1)
A_stacked = np.empty((max_length, N, N), dtype=A.dtype)
B_stacked = np.empty((max_length, N), dtype=B.dtype)
solve_triangular(a,b)は、が三角行列であると仮定して、方程式
を
について解く
以下では、方程式
および
をについて解くことで各時刻の
および
の値を求めている。
計算された値はA_stackedとB_stackedにそれぞれ保存される。
for t in range(1, max_length + 1): At = A / t Bt = B / t # bilinear A_stacked[t - 1] = la.solve_triangular( np.eye(N) - At / 2, np.eye(N) + At / 2, lower=True ) B_stacked[t - 1] = la.solve_triangular( np.eye(N) - At / 2, Bt, lower=True )
それではこれをHiPPO-LegSの初期化操作に追加しよう。 以下のコードではPyTorchのregister_buffer()を使用する。 register_buffer()によって、 nn.Moduleの中で、最適化されるパラメータ以外のパラメータを定義することができる。例えば、以下のコードではA_stackedやB_stackedはmodel.parametersでは出てこない(最適化パラメータではない)が、model.state_dictでは出てくる(保存が可能)。
class HiPPOScale(nn.Module): """Vanilla HiPPO-LegS model (scale invariant instead of time invariant)""" def __init__(self, N, max_length=1024): """ max_length: maximum sequence length """ super().__init__() self.N = N A, B = transition(N) B = B.squeeze(-1) A_stacked = np.empty((max_length, N, N), dtype=A.dtype) B_stacked = np.empty((max_length, N), dtype=B.dtype) for t in range(1, max_length + 1): At = A / t Bt = B / t # bilinear A_stacked[t - 1] = la.solve_triangular( np.eye(N) - At / 2, np.eye(N) + At / 2, lower=True ) B_stacked[t - 1] = la.solve_triangular( np.eye(N) - At / 2, Bt, lower=True ) self.register_buffer("A_stacked", torch.Tensor(A_stacked)) # (max_length, N, N) self.register_buffer("B_stacked", torch.Tensor(B_stacked)) # (max_length, N) def forward(self, inputs): """ inputs : (length, ...) output : (length, ..., N) where N is the order of the HiPPO projection """ # 時系列信号を入力としてLTI方程式を解き、係数ベクトル c の時間発展を計算する ... def reconstruct(self, c): # 係数ベクトル c から、現在までの時系列信号を再構成する ...
forward()の実装
forward()では式(1)の計算を行い、各時刻の係数ベクトルcを逐次的に求める。次のように実装されている。
class HiPPOScale(nn.Module): ... def forward(self, inputs): """ inputs : (length, ...) output : (length, ..., N) where N is the order of the HiPPO projection """ L = inputs.shape[0] inputs = inputs.unsqueeze(-1) x = torch.transpose(inputs, 0, -2) x = x * self.B_stacked[:L] x = torch.transpose(x, 0, -2) # (length, ..., N) c = torch.zeros(x.shape[1:]).to(inputs) cs = [] for t, f in enumerate(inputs): c = F.linear(c, self.A_stacked[t]) + self.B_stacked[t] * f cs.append(c) return torch.stack(cs, dim=0) ...
forward()の前半では係数cの初期ベクトルを作成する。
L = inputs.shape[0] inputs = inputs.unsqueeze(-1) x = torch.transpose(inputs, 0, -2) x = x * self.B_stacked[:L] x = torch.transpose(x, 0, -2) # (length, ..., N) c = torch.zeros(x.shape[1:]).to(inputs)
後半で式(1)の計算を逐次的に行い、最後にcsをTensor形式で結合する。 torch.stackでは新しいdimを作成し、そのdimに沿ってテンソルを連結することができる。
cs = [] for t, f in enumerate(inputs): c = F.linear(c, self.A_stacked[t]) + self.B_stacked[t] * f cs.append(c) torch.stack(cs, dim=0)
それでは時系列信号uを入力してHiPPO係数を計算してみよう。
hippo = HiPPOScale(N=N, max_length=int(T / dt)+1).to(device) cs = hippo(u)
HiPPO係数は以下のように計算される。
# print(cs.shape)
# print(cs)
torch.Size([8001, 64])
tensor([[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 2.3562e-04, 2.7207e-04, 1.5053e-04, ..., 1.9469e-11,
-2.3281e-11, 1.7233e-11],
[ 1.1005e-02, 1.4125e-02, 9.9080e-03, ..., 6.9807e-10,
-2.7768e-10, -5.0084e-10],
...,
[ 6.1107e-01, -4.5706e-01, -3.7144e-01, ..., 4.1828e-03,
-2.0363e-02, -1.4803e-02],
[ 6.1086e-01, -4.5731e-01, -3.7155e-01, ..., 4.1581e-03,
-2.0260e-02, -1.4424e-02],
[ 6.1066e-01, -4.5755e-01, -3.7165e-01, ..., 4.1496e-03,
-2.0141e-02, -1.4033e-02]])
信号の再構成
最後にHiPPO係数から時系列信号を再構成してみる。これはHiPPOによって作成された記憶を頼りに、過去の信号履歴を復元する操作である。
まず]の区間で時間グリッドを用意する。
vals = np.linspace(0.0, 1.0, max_length)
測度関数
def measure_fn(c=0.0): # legs fn = lambda x: np.heaviside(x, 1.0) * np.exp(-x) fn_tilted = lambda x: np.exp(c * x) * fn(x) return fn_tilted measure = measure_fn()(vals)
基底関数
LegSで用いられる直交基底であるLegendre多項式を計算しておく。
def basis(N, vals, c=0.0, truncate_measure=True): """ vals: list of times (forward in time) returns: shape (T, N) where T is length of vals """ # legs _vals = np.exp(-vals) eval_matrix = ss.eval_legendre(np.arange(N)[:, None], 1 - 2 * _vals).T # (L, N) eval_matrix *= (2 * np.arange(N) + 1) ** 0.5 * (-1) ** np.arange(N) if truncate_measure: eval_matrix[measure_fn()(vals) == 0.0] = 0.0 p = torch.tensor(eval_matrix) p *= np.exp(-c * vals)[:, None] # [::-1, None] return p eval_matrix = torch.Tensor((B[:, None] * ss.eval_legendre(np.arange(N)[:, None], 2 * vals - 1)).T)
0~6次のLegendre多項式を以下に図示する。

再構成
HiPPOにより求めた係数cから時系列信号を再構成する。これは係数と基底行列の積を取ることで求められる。
rec = eval_matrix.to(cs) @ cs.unsqueeze(-1)
plt.figure(figsize=(14, 5)) offset = 0.0 plt.plot(vals, u.cpu() + offset, "k", linewidth=1.0, label="input $u(t)$") plt.plot(vals, rec[-1], label="HiPPO reconstruction", color="red") plt.xlim(0,1) plt.legend()

まとめ
以上、HiPPOによる著者実装を見てきた。実装は極めてシンプルで、直交基底に対する各基底の係数を式(1)で時間発展させることで、時系列データをモデリングすることができた。このように簡略な数値計算で強力な時系列モデリングを実現する理論的枠組みの強力さを再認識した。
参考文献
時系列モデリング手法 HiPPO を読み解く(1)
ICLR2022で発表された、新しい時系列モデリング手法としてS4(Structured State Space Sequence model)というものがある。S4は長距離ベンチマークで従来手法を圧倒的性能で破って話題となった。
S4の論文はいくつかの研究の集大成となっており、核となる技術としてHiPPO (Recurrent Memory with Optimal Polynomial Projections)というものがある。そこで論文と著者実装を通じて、HiPPOとはどんなものなのかを理解することを目指す。
実装編はこちら。 dosuex.com
概要
まずはHiPPOの概要を記載する。

時系列データからの学習における中心的な問題は、累積する履歴に応じて、圧縮された「表現」を逐次的に更新することである。
本研究では、連続信号や離散時系列を多項式基底への射影により逐次的に圧縮するためのフレームワーク(HiPPO)が開発された。
HiPPOは、過去の各時間ステップの重要度を与える測度(重み)が与えられると、逐次関数近似問題に対する最適解を求めることができる。 さらにHiPPOを拡張して、すべての履歴を記憶するために、時間スケールの変化に対して不変性を持つ新しい記憶更新機構(HiPPO-LegS)を作ることができる。 HiPPO-LegSは、タイムスケールに対するロバスト性、高速なアップデート、有界な勾配といった利点を持っており、本研究の集大成に当たる。
ベンチマークである、Permuted MNISTにおいて、HiPPO-LegSは98.3%の最新精度を達成した。また、時間スケールや欠損データに対するロバスト性をテストする軌道分類タスクにおいて、HiPPO-LegSはRNNとニューラルODEのベースラインを25~40%の精度で上回った。
背景
時系列データからの学習は現代の機械学習の基本的な課題であり、言語モデル、音声認識、動画処理、強化学習のようなタスクに通じるものである。
長期間にわたる複雑な時間依存関係をモデル化する中心的な課題は「記憶」をどのような表現として保持するかである。記憶を内部状態として扱う、深層学習時系列モデリングの手法は次のようなものがある。
- RNN:長時間にわたる時系列情報では勾配消失問題が発生することが知られている。
- LSTM:サンプリングレートなどの変化によって起きる、時間スケールの変化に弱いことが知られている。
本研究で記憶の扱いに関して新しく得られた洞察は、記憶の保持・更新を逐次関数近似の問題として定式化したことである。
これにより、時系列関数はいくつかの基底関数に対する最適な係数を保存することによって低次元情報で近似される。この近似は、過去の各時刻の重要度を表す測度とともに評価される。
HiPPO(high-order polynomial projection operators)とは、任意の関数を与えられた測度のもとで直交関数系の係数空間に射影するものであり、これが時系列情報を圧縮して記憶として保持する操作に相当する。さらに時系列情報が更新されるに応じて、係数も時間発展させることができ、これが記憶を更新する操作に相当する。
記憶のモデリング
ここから、本研究での記憶の扱い方を数式を使って少しづつ具体化していく。
問題設定
時系列関数 において、過去の履歴
を元にして未来を予測したい。しかし過去の履歴を完全に記憶することは難しいため、何かしら履歴を圧縮した記憶として保持する必要がある。
関数空間での距離
ふたつの関数と
の距離を計算するために、以下のように関数の内積を定義する。
ここでは測度と呼ばれる量である。測度は点
における「重み」とイメージすると良い。
これにより関数の
ノルムも
定義することができる。
多項式展開
時系列関数を何かしらの基底関数の多項式を用いて、関数
で近似することを考える。
これにより複雑な時系列関数の振る舞いを、有限個の係数列の情報へと圧縮することができる。
なお本論文では基底関数として直交多項式を用いている。直交多項式は、直交性(次数の異なる基底関数同士の内積がゼロとなる)性質を持ち関数近似の領域でよく使われる手法である。
関数の多項式展開の身近な例として、フーリエ多項式などが挙げられる。
逐次近似
各時刻において
を逐次的に近似関数
を求めたい。これは
において定義される測度
を用いて
となるような近似関数 を求めることに相当する。
HiPPOフレームワーク
以上で立てた方針を、具体的な手順にまとめていく。
逐次関数近似の方針
時系列関数を近似する関数
は、任意の基底におけるその展開のN個の係数で表現することができる。
まず、適切な基底を選択する。
近似理論の古典的な手法を活用すると、自然な基底は測度に対する直交多項式の集合であり、これは直交基底を形成する。このとき直交性により各基底の係数は
で得ることができる。
次に、係数 に対する時間微分を計算する。
は
のダイナミクスによって決められる常微分方程式(ODE)に従って時間発展する。
逐次関数近似アルゴリズム
まずHiPPOを以下のように定義する。
で定義される時間変化する測度
、多項式のN次元部分空間
、および連続関数
が与えられたとき、HiPPOは以下の性質を持つ射影演算子
と係数抽出演算子
を時間
ごとに定義する。
(1) は時間
までに制限された関数
を取り、近似誤差
を最小化する多項式 に写像する。(図1 (1)~(2))
(2) 係数抽出演算子 は多項式
を、測度
に対して定義された多項式直交基底の係数ベクトル
に写像する。(図1 (2)~(3))
演算子と
を連鎖させてできる演算子を
と呼ぶことにする。すなわち
である。
筆者らの導出により係数関数 はODE
に従って時間発展する(図1 (3))。
このODEを離散化して解くことで を逐次的に求めることができる(図1 (4))。なお、この微分方程式を線形時間不変(linear-time-invariant; LTI)方程式と呼ぶ。

様々な測度族とHiPPO
本研究の主たる理論的結果は、様々な測度族 (図2)に対してHiPPOを導出したことである。

translated Legendre (LegT) 測度
LegT測度
は最近の履歴 ] に対して一様な重みを付与する(図2:左)。要約される履歴の長さを表すハイパーパラメータ
が存在する。
LegT測度のもとでLTI方程式(式(1))の は次のように与えられる。(導出は参考文献1の付録Dを参照)
translated Laguerre (LagT) 測度
LagT測度
は指数関数的に減衰する重みを使用し、最近の履歴をより重要視する(図2:中央)。
LagT測度のもとでLTI方程式(式(1))の は次のように与えられる。(導出は参考文献1の付録Dを参照)
HiPPO-LegS: Scaled Measures for Timescale Robustness
これまで見てきたように、測度関数に何を選択するかが記憶機構の特性を決定していた。したがって、より適切な測度を選択することで、より優れた理論的特性を持つ記憶機構を作ることができそうだ。
信号処理ではスライド窓関数が一般的であるが、記憶に対するより直感的なアプローチは、忘却を避けるために時間と共に窓関数をスケーリングすることである(図1:右図)。これを scaled Legendre measure (LegS) 測度と呼ぶ。
scaled Legendre measure (LegS)
LegS測度
は全履歴に対して一様な重みを付与する。 LegSのもとでのLTI方程式
の係数行列は次のように与えられ
さらにLTI方程式は以下のように離散化される。
微分方程式を離散化すると一般に時間ステップ が式に含まれることになるが、上の式では
が含まれていないことに注目して欲しい。これはすなわちLegSが時間スケールに対して不変であることを反映している。この特徴によって、LegSの時間スケールに対するロバスト性が保証される。
詳細は割愛するが、その他にもLegSは
- 計算の効率性が高い
- 勾配消失が起こらない
- 誤差が入力の滑らかさに応じて減少する
などの特徴を持つ。
図3にHiPPOによる逐次関数近似の様子を示す。現時刻に近い領域は微細な構造まで近似されているが、遠い過去の領域は大まかな傾向だけつかんだトレンドライン近似となっていることがわかる。

性能評価
評価実験によって、HiPPOの系列モデリングの評価およびHiPPO-LegSの時間スケールロバスト性が確認されている。
Sequential Image Classification on Permuted MNIST
Permuted MNISTとはMNISTのピクセルの並び順を別の順序で置換し、この置換を全てのデータに対して施したデータセットである(図4)。予測モデルに対してはピクセルを並べたベクトルが入力される。置換操作により、クラス数(1~9の9個)は保たれたまま局所構造が破壊されるので、ラベルの予測のためにはピクセル間の長期的な相関関係を捉える必要がある。

表1がPermuted MNISTの予測結果である。HiPPOがLSTMやTransformerといった、現在の主流となっている手法を超えていることがわかる。

HiPPO-LegSの時間スケールロバスト性
Character Trajectories dataset では固定のサンプリングレートで記録したのペン先軌道の測定値から、文字を分類することを目的としている(図5)。

時間スケールのロバスト性を確認するために、学習データとテストデータのサンプリングレートを変えて性能を評価する。表2の100Hz→200Hzがテストデータでサンプリングレートを引き上げた場合であり、200Hz→100Hzが引き下げた場合である。いずれも、従来の手法がサンプリングレートの変化にほとんど対応できていないのに対して、HiPPO-LegSが強いロバスト性を持っていることがわかる。
また欠損値(Missing values)を含む場合に対するテスト結果が表2の下部に記載されている。こちらも従来手法たちを大幅に超える結果を出していることがわかる。

まとめ
HiPPO(high-order polynomial projection operators)とは、任意の関数を与えられた測度のもとで直交関数系の係数空間に射影するものであり、この係数を時間発展させることで、逐次的な関数近似を実行する。
参考文献
Pythonの辞書の欠損キー操作:setdefaultとdefaultdict
Pythonで辞書に存在しないキーで操作する際は、get()、setdefault()、defaultdict()などのメソッドを用いると良い。
get()による欠損キーへのアクセスは以下を参照。
setdefault()とdefaultdict()はよく似た挙動をするが、できる限りdefaultdict()を使う方が望ましい。
以下では、foodsという辞書がvegetableなどのカテゴリーをキーとして、set()内にcarrotのような具体的な食材を保持している状況を考える。
foods = {
"vegetable": {"carrot"},
"drink": {"water", "coffee"}
}
まだ存在しないキーfruitsに新しい食材orangeを追加してみる。
get()による値の追加
get()メソッドはキーが存在しなかった場合に返す値を第二引数に設定できる。新しいキーfruitsが存在しなかった場合、空のセットを返しorangeをセットに追加し、fruitsに対して再代入する。
fruits = foods.get("fruits", set()) fruits.add("orange") foods["fruits"] = fruits print(foods)
get()による値の追加
setdefault()メソッドを使うと、先ほどの処理を1行で書くことができる。
foods.setdefault("fruits", set()).add("orange") print(foods)
setdefaultよりdefaultdictを使おう
setdefault()によりコードはシンプルになったが、場合によっては効率的でないことがある。例えば、次のようなクラスのインスタンスが持つ辞書によって、動的に内部状態を管理することを考える。
class Foods: def __init__(self): self.data = {} def add(self, category, food): self.data.setdefault(category, set()).add(food)
このクラスのユーザーは以下のように値を追加することができる。
foods = Foods() foods.add("fruits", "orange") foods.add("bread", "bagel") print(foods.data) # {'fruits': {'orange'}, 'bread': {'bagel'}}
しかし問題点がひとつある。foods.add()が呼ばれるたびに、キーの欠損の有無に関わらず、必ず一度setインスタンスの作成が行われている。コストのかかる余分なインスタンスの割り付けを回避するために、defaultdictクラスを使うと良い。
組み込みモジュールcollectinosのdefaultdictクラスには、キーが存在しない場合のデフォルト値生成関数を指定することができる。これにより、キーが存在しない場合に限り、デフォルト値の生成が実行される。defaultdictを使ってFoodsクラスを書き換える。
from collections import defaultdict class Foods: def __init__(self): self.data = defaultdict(set) def add(self, category, food): self.data[category].add(food)
使用方法はsetdefault()のときと同じであるが、内部のメモリ効率が向上している。
foods = Foods() foods.add("fruits", "orange") foods.add("bread", "bagel") print(foods.data) # defaultdict(<class 'set'>, {'fruits': {'orange'}, 'bread': {'bagel'}})
参考
リンク